This chapter describes how to implement the algorithm that you have identified as a candidate for acceleration and provides a hardware reference for the RASC Algorithm Field Programmable Gate Array (FPGA) hardware. It covers the following topics:
-

Note: Make sure that you read the section called “Major Technical Changes in the RASC 2.20 Release” on the “New Features in This Guide” page in the frontmatter of this manual.
Figure 3-1 shows a block diagram of RASC Core Services. The Core Services is made up of all the functional blocks excluding the algorithm block. Core Services is user independent and is pre-synthesized. The algorithm block is specific to the user algorithm and evolves through the RASC design flow. In the RASC 2.20 release, Core Services has new features that increase the bandwidth and reduce the latency as perceived by the algorithm. The components of Core Services are described in “Core Services Architecture Overview”.
The RASC algorithm FPGA is a Xilinx Virtex 4 LX200 part (XC4VLX200-FF1513-10). It is connected to an SGI Altix system via the SSP port on the TIO ASIC and loaded with a bitstream that contains two major functional blocks:
The reprogrammable Algorithm Block
The Core Services Block that facilitates running the algorithm.
Core Services is the key component of RASC which facilitates execution of the user algorithm in the algorithm block. It helps in synchronizing the I/O, memory, and Algorithm Block operations. This section describes the services provided by the Core Services Block of the RASC FPGA. These features include:
Scalable System Port (SSP) Implementation: physical interface and protocol
Global Clock Generation and Control
Independent read and write ports to each of the three logical or five physical random access memories (SRAMs)
Single-step and multi-step control of the Algorithm Logic
Independent direct memory access (DMA) engines for read and write data (two read DMA in the Input DMA block and two write DMA engines in the Output DMA block)
Both block DMA and stream DMA are supported (for more information on stream DMA see Chapter 5, “Direct I/O”)
Programmed Input/Output (PIO) access to algorithm's Debug port and algorithm defined registers
Control and Status registers
Host and FPGA process synchronization capabilities, including interrupts and atomic memory operations (AMOs).
The Core Services in the RASC 2.20 release have new direct memory access streaming capabilities that increases bandwidth and reduce latency as perceived by the algorithm. This describes the components of Core Services as shown in Figure 3-1.

The Programmed Input/Output (PIO) request engine handles the host write and read requests for individual 64-bit values.
The memory mapped register (MMR) block houses and handles the registers used to control and use the FPGA.
The interrupt generator assembles the proper packet data to interrupt the host in the case of a direct memory access (DMA) done or alg_done, for example.
The input direct memory access (DMA) block is comprised of up to four stream DMA engines that target the algorithm for the data coming in from main memory and a block DMA read engine that targets SRAM for the data coming in from main memory.
The output DMA block is comprised of up to four stream DMA engines that take data directly from the algorithm and target main memory and a block DMA write engine that takes data from SRAM and targets main memory.
The Memory Controller handles the memory interfaces and is responsible for arbitrating between sources and destinations. It provides a generic interface to the algorithm for accessing on-board memory.
The Core Services Logic provides the mechanism for application and debugger software to run the Algorithm Block in one of two modes: Normal Mode or Debug Mode. In Normal Mode, the algorithm is enabled to run and allowed to run to completion uninterrupted. In Debug Mode, the algorithm is enabled to run but forced to execute in blocks of one or more steps, allowing the user to stall the algorithm at intermediate points in the execution and query intermediate internal values. A step could be as small as one Algorithm Block clock cycle, or an adhoc size defined by Algorithm Block logic. Core Services Logic continues to run more or less normally regardless if in Normal or Debug Mode. For a description of how the Algorithm Block can use the debug mode hooks, see the “Algorithm Interfaces ”.
This section defines the interface signals between the Algorithm Block and the Core Services Block and algorithm defined registers (ADRs). It covers the following topics:
There are control signals to enable the smooth transition of control from Core Services to the algorithm and back. These signals are listed and explained in Table 3-1.
Table 3-1. Algorithm Control Interface Signals
Signals | Direction | Description |
|---|---|---|
clk | input | The algorithm clock is available at frequencies of 50, 66, 100, and 200 MHz. This clock signal is gated, synchronous and phase aligned to the core_clk used in Core Services. The clock frequency is determined by a macro defined at synthesis of the FPGA bitstream. The clock is driven on global clock buffers for low skew routing. |
clk_s | input | The optional supplemental clock has a frequency that is determined by macro definitions at synthesis of the FPGA bitstream to any frequency n/m * 200 MHz, where n and m are five-bit integers. The clock is driven on global clock buffers for low skew routing. Note that a supplemental clock, whose cycles are not of a multiple of 5 nanosecond (ns), needs to be considered asynchronous to clk and appropriate logic must be added to handle properly the clock domain crossings between clk and clk_s. |
rst | input | Resets the algorithm logic. The algorithm logic is always put into reset for four clock cycles synchronous to clk before triggering it to execute. |
step_flag_out | output | Step boundary indicator flag. For every clock cycle that the step_flag signal is asserted, it signals to Core Services that one step has been completed. The Core Services logic ignores this signal when the algorithm is not run in debug mode. |
alg_done | output | Set when the algorithm has finished processing. This can either be set and held until the algorithm is reset or pulsed. When alg_done is asserted, clk will become inactive the following clock cycle. The signal alg_done must clear when rst is asserted. |
The Algorithm Defined Registers (ADRs) are bidirectional, that is, they can be read or written to by the algorithm. ADRs can be read and/or written to by both the host and algorithm. This gives a simple mechanism for an algorithm to forward information to future invocations of the algorithm. The write capability overlaps the debug registers up to RASC 2.20. All ADR signals are synchronous to clk.
There are hooks to implement from one to 64 ADRs. By default, eight ADRs are included. If a different number is required, change the user_space_wrapper and alg_block_top configuration files. The ADR Verilog module is parameterized, which should minimize the need to make changes when changing the quantity of these registers.
The ADR signal definitions are provided in Table 3-2.
Table 3-2. ADR Signal Definitions
Signals | Direction | Description |
|---|---|---|
alg_def_reg<n>[63:0] | input | Current value of ADR n |
alg_def_reg_updated[<n>] | input | Asserted one clock cycle when alg_def_reg<n> is updated by the host. Can be left unconnected if not used. |
alg_def_reg_polled[<n>] | input | Asserted one clock cycle when alg_def_reg<n> is read (polled) by the host. Can be left unconnected if not used. |
alg_def_reg_write_[<n>] | output | Assert this signal to write to alg_def_reg<n>. The signal alg_def_reg<n>_wr_data must be valid. The value will appear in alg_def_reg<n> the next clock cycle. A simultaneous write from the host supersedes this operation and this write will be ignored. In the event this happens, alg_def_reg<n>_updated will be asserted the following cycle. |
alg_def_reg<n>_wr_data[63:0] | output | Value to write to alg_def_reg<n> when alg_def_reg_<n>_write is asserted. |
The following Verilog macros must be defined in the alg.h file. By setting the first macro, up to 64 ADRs can be defined. Note that a setting other than 8 requires changes to user_space_wrapper and alg_block_top.v configuration files. The remaining macros are bit masks that allow you to optimize by restricting usage, for example, making the ADR read-only by the host. The macros are, as follows:
// number of ADRs to implement `define ADR_REG_NUM 8 // bit mask to specify which ADRs to implement `define ADR_REG_IN_USE `ADR_REG_NUM'hff // bit mask to specify which ADRs are read-only by alg `define ALG_ADR_READ_ONLY `ADR_REG_NUM'hff // bit mask to specify which ADRs are read-only by host `define HOST_ADR_READ_ONLY `ADR_REG_NUM'h00 // bit mask to specify which ADRs are write-only by host `define HOST_ADR_WRITE_ONLY `ADR_REG_NUM'h00 |
The host first writes to alg_def_reg<n>, then reads it. Subsequently, the algorithm does a write (see Figure 3-2). These signals represent what the algorithm sees as a result of both host initiated actions and algorithm initiated actions.

This section describes streaming direct memory access (DMA) and covers the following topics:
In streaming DMA, the direct memory access transfers data back to host memory automatically after it receives the data from the algorithm. When the algorithm completes, it asserts the flush signal and waits for the return of the flushed signal before it terminates itself. See the descriptions of the strm_out_<n>_flush strm_out_<n>_flushed signals in Table 3-4.
Table 3-3 shows the signal definitions of the input streaming DMA engine.
Table 3-3. Input Streaming DMA Engine Signal Definitions
Signals | Direction | Description |
|---|---|---|
strm_in_<n>_data[127:0] | input | Input stream data. Valid when strm_in_<n>_data_vld is asserted. |
strm_in_<n>_data_rdy | input | When asserted, data in the input stream is available. strm_in_<n>_data is valid. |
strm_in_<n>_data_vld | input | When asserted, strm_in_<n>_data is valid. |
strm_in_<n>_complete | input | A one cycle pulse means that the transfer of data for this stream is complete. This can be asserted at the same time as the last assertion of strm_in_<n>_data_vld or sometime after. |
strm_in_<n>_rd_en | output | Assert this signal to read from the input stream buffer. If there is no data in the buffer, this signal has no effect. If the input stream is to be treated as a FIFO, this signal can be used as a pop signal. The logic, when it sees an asserted strm_in_<n>rd_en signal, will deliver the next datum if and only if data is available. Otherwise, the signal is ignored. |
This timing diagram shows the sequence to start an input stream (see Figure 3-3). In prior RASC releases, there was a delay of a couple cycles between assertion of the rd_en and data_vld signals. The new strm_in_<n>_data_rdy signal eliminates this delay or the need to poll to determine if data is available to the algorithm.

This timing diagram shows the end of an input stream (see Figure 3-4).

Table 3-4 contains signal definitions for the output stream DMA engines. There are four instantiations of the engine.
Table 3-4. Output Stream Signal Definitions
Signals | Direct | Description |
|---|---|---|
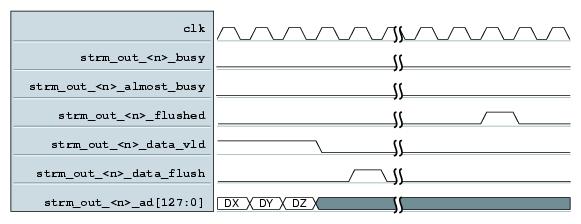
strm_out_<n>_busy | input | When asserted, the buffer in output stream logic is full. strm_out_<n>_data_vld must be deasserted within two cycles. |
strm_out_<n>_almost_busy | input | When first asserted, it may become necessary to deassert strm_out_<n>_data_vld within 256 cycles. |
strm_out_<n>_flushed | input | All previously sent data has been flushed to memory. The algorithm must assert strm_out_<n>_flush if it expects strm_out_<n>_flushed to return. The flushed signal is intended to give the algorithm a guarantee that all outstanding writes to host memory have been completed prior to an alg_done interrupt. When using SRAM for multi-buffering, the algorithm knows all the data has been transferred to SRAM with the last write to SRAM, after which it can signal alg_done. In this case, it is guaranteed that all the data will be in SRAM by the time the DMA to read the SRAM starts. In the case of streaming, there is potential for a race condition where the interrupt following an alg_done, without a flush signal asserted, arrives before all of the data is written to host memory. |
strm_out_<n>_data_vld | output | Assert when strm_out_<n>_ad_out is valid. This signal should not be asserted if strm_out_<n>_flush was previously asserted and strm_out_<n>_flushed has not yet been asserted. |
strm_out_<n>_flush | output | Assert at the end of an output stream. This signal is used to guarantee data previously delivered to the output stream has been sent to host memory. strm_out_<n>_data_vld should not be asserted until strm_out_<n>_flushed has been asserted. |
strm_out_<n>_ad[127:0] | output | Three possible types of data for this signal are, as follows: system address, byte count, or data. Currently, only the data is supported. |
strm_out_<n>_data_last | output | Assert at the end of an output stream. Assertion of this signal obviates the need for the algorithm to pad the output data. Assertion of strm_out_<n>_data_last also signals the corresponding DMA engine to terminate the current DMA after all outstanding writes to host have been completed. This allows the algorithm to terminate the DMA without the need to deliver all the data specified for the transfer. |
This timing diagram shows the sequence to start an output stream (see Figure 3-5) and the flow control necessary when the output stream becomes busy.

Figure 3-6 shows the end of an output stream. Note that the flush signal can be asserted any time during or after the final assertion of strm_out_<n>_data_vld.
The extractor statements for DMA streaming are in the form of // extractor stream:<stream_name> <stream #> <stride>, as follows:
// extractor STREAM_IN:in_a 0 0 // extractor STREAM_IN:in_b 1 0 |
A stride is the minimum size (in bytes) of a piece of data that is guaranteed to not have dependencies with other same-sized blocks of data in the input stream. A stride of 0 means that no such data exists and that the input stream may not be broken apart and spread across FPGAs.
There are four DMA stream engines. Four data stream pointers are defined in the following extractor statement:
| * stream numbers
V
// extractor STREAM_IN:in_a 0 0
// extractor STREAM_IN:in_b 1 0
// extractor STREAM_IN:in_c 2 0
// extractor STREAM_IN:in_d 3 0
// extractor STREAM_OUT:out_a 0 0
// extractor STREAM_OUT:out_b 1 0
// extractor STREAM_OUT:out_c 2 0
// extractor STREAM_OUT:out_d 3 0
|
The arrow above the extractor statement points to the stream number. You can use multiple stream DMAs simultaneously, but total transfer rate remains the same. The bandwidth is evenly divided among active streams.
There are hooks to implement from zero to 64 debug registers. By default, sixty-four debug registers are included. If you require a different number, you must make changes to user_space_wrapper and alg_block_top.
Table 3-5. Debug Register Definition
Signal Name | Direction | Description |
|---|---|---|
debug<n>[63:0] | output | Current Value of Debug n |
This Verilog module is also parameterized, so the needed changes should be minimal.
This section describes the SRAM interface and covers the following topics:
The algorithm may run concurrent to the Core Services. This means that you must be careful when assigning the ports at the SRAM interface. When designing an algorithm, you can no longer rely on inherent arbitration that comes from running the master (algorithm or Core Services), exclusively.
If a situation is created, where a particular external SRAM port is being accessed by Core Services (via some host action such as a DMA or PIO) and also by the algorithm, simultaneously, causing an access conflict. Core Services and the algorithm must go through arbitration to gain access to the port when an access conflict exists. If you schedule an implementation where an access conflict to a port can occur, you must design your algorithm implementation to handle the arbitration activity that can occur. If you schedule your implementation where no access conflict can occur, no accommodations must be implemented to deal with the arbitration.
You can still assign the ports to avoid any arbitration by using extractor statements and directives.
You may assign ports in the alg.h file through `define statements. An example of allowing the algorithm to read from SRAM Bank 0 and write to SRAM Bank 1 is, as follows:
//////////////////////////////////////////// // Specify SRAM ports for algorithm // //////////////////////////////////////////// `define alg_uses_sram0_rd `define alg_uses_sram1_wr |
You may also define the port usage for Core Services. This is done through extractor statements in the Verilog. An example of assigning the Core Services the write port of SRAM Bank 0 and the read port of SRAM Bank 1 is, as follows:
// A multiple-source error is generated if a destination output is targeted // by more than one input source. (captured in the bit 0 of debug register 9) // // extractor CS: 1.0 // extractor VERSION:19.1 // extractor SRAM:op_in0 1024 64 sram[0] 0 in u stream // extractor SRAM:res0 1024 64 sram[1] 0 out u stream |
For a more detailed discussion of the extractor statements, please see “Adding Extractor Directives to the Source Code” in Chapter 7.
There are two handshaking techniques available. You may use either the busy signal methodology or the crediting scheme. Only one method is needed on each interface and you may select one method for one interface and the other method for a second interface.
If, however, it is guaranteed that the algorithm and DMA will never use the same SRAM port, neither of the schemes described below are required.
The busy signal method is a straight forward back pressure method to indicate to the algorithm that it must stall its SRAM write queue until the SRAM is available. This is signaled by the SRAM interface by asserting the mem_<n>_rd_busy or mem_<n>_wr_busy signal with a high value.
The algorithm must deassert the mem_<n>_rd_cmd_vld and mem_<n>_wr_cmd_vld signal two clocks after the interface asserts busy and may not assert it until the busy signal is no longer asserted.
The interface indicates that space is available for a 128-bit transfer by pulsing the mem_<n>_rd_fifo_cred or mem_<n>_wr_fifo_cred signal high for one clock period. For example, after reset if the SRAM can handle sixteen (16) 128-bit transfers, the interface asserts the proper credit signal for sixteen (16) clocks. Furthermore, as a previously full buffer slot is freed, a credit is sent back to the algorithm indicating that there is room for another transfer.
In the crediting scheme, the algorithm must maintain a credit counter and it must not send data when there are no credits available. Credit overflow and underflow are the responsibility of the algorithm designer.
There are three acceptable and mutually exclusive memory configurations allowed in RASC Core Services. The first is the same as the configuration found in the prior RASC 2.1 release. This configuration pairs up two 64-bit memory ports to be used as a 128-bit memory. There is a fifth 64-bit memory port available in this configuration.
A new configuration is available in the RASC 2.20 release (and later) that enables five 64-bit memory ports. All five of these ports are independent and can be configured individually.
You may also decide that you do not need memory ports and all data will flow in and out through the streaming DMA engines. This enables an area optimization by removing the memory interfaces from the integrated design.
Each memory configuration can also be defined as algorithm access only (no DMA).
The SGI RASC Algorithm Configuration tool allows you to configure memory resources. For more information, see “Memory Configuration” in Chapter 8.
Note that the address offsets of the alg_mem_<n>_offset macro were changed from bits 9:0 to 23:14 in the RASC 2.1 release. Bits 31:24 are ignored.
Table 3-6. SRAM Interface Signal Definition
Signals | Direction | Descriptions |
|---|---|---|
mem_<n>_rd_cmd_vld | output | When asserted, mem_<n>_rd_addr is valid. Some number of cycles later mem_<n>_rd_data_vld and mem_<n>_rd_data will be asserted with valid data. After the assertion of mem_<n>_rd_busy, this signal must be deasserted within two cycles. |
mem_<n>_wr_cmd_vld | output | When asserted, mem_<n>_wr_addr, mem_<n>_wr_be, and mem_<n>_wr_data are valid. After the assertion of mem_<n>_wr_busy, this signal must be deasserted within two cycles. |
mem_<n>_rd_busy | input | When asserted, this signal indicates the mem_<n>_rd_cmd_vld signal must be deasserted within two cycles. |
mem_<n>_wr_busy | input | When asserted, this signal indicates the mem_<n>_wr_cmd_vld signal must be deasserted within two cycles. |
mem_<n>_rd_fifo_cred | input | This signal is asserted for one clock period for each available location in the command FIFO. After reset, the core services will assert mem_<n>_rd_fifo_cred for the number of locations available. As commands enter the FIFO, the algorithm should decrement its credit counter. The core services will assert mem_<n>_rd_fifo_cred following the processing of the command, and the algorithm will increment its credit counter acknowledging the available location. |
mem_<n>_wr_fifo_cred | input | Identical to the mem_<n>_rd_fifo_cred signal, but for writes. |
mem_<n>_wr_be[15:0 or 7:0] | output | This signal is used to indicate a write enable of 64 bits of mem_<n>_wr_data. For a 64-bit port, bit 0 is used for bits [63:0], and for a 128-bit port, bits 0 and 8 are used for bits [63:0] and [127:64], respectively. |
mem_<n>_rd_addr[23:0 or 22:0] | output | For a 128-bit port, this signal indicates the byte address for a memory read (or write) request. The lower four bits must be zero. For a 64-bit port, this signal has a 23 bit address and only the last 3 bits need to be zero. |
mem_<n>_wr_addr[23:0 or 22:0] | output | For a 128-bit port, this signal indicates the byte address for a memory read (or write) request. The lower four bits must be zero. For a 64-bit port, this signal has a 23 bit address and only the last 3 bits need to be zero |
mem_<n>_wr_data[127:0 or 63:0] | output | This signal is the data for a memory write access. |
mem_<n>_rd_data_vld | input | When asserted, mem_<n>_rd_data is valid. |
mem_<n>_rd_data[127:0 or 63:0] | input | Data from a previous read request. Data is returned in the order requested. |
mem_<n>_error | input | When asserted, this signal indicates an uncorrectable read data error occurred during a memory access. |
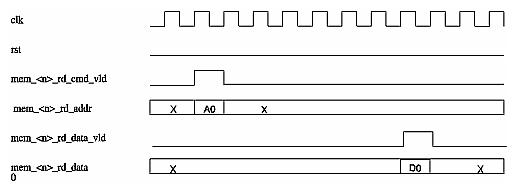
Figure 3-7 shows a read of four cycles, no busy.

Figure 3-8 shows a read of eight cycles with busy. Note that mem_<n>_rd_cmd_vld must be deasserted two cycles after assertion of busy.
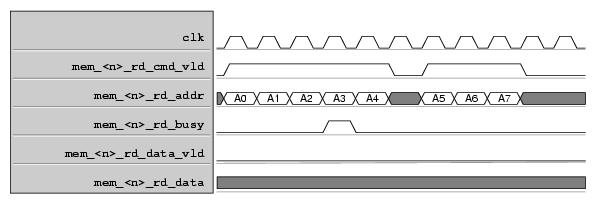
Figure 3-9 shows a write of eight cycles with busy. Note that mem_<n>_wr_cmd_vld must be deasserted two cycles after assertion of busy.

This section provides information that the algorithm designer needs to implement the hardware accelerated algorithm within the FPGA and the Core Services Block framework. It covers the following topics:
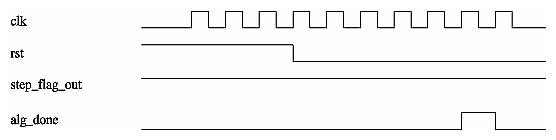
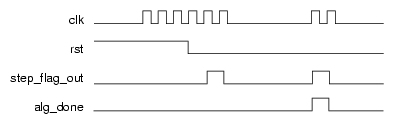
This section covers the general algorithm control sequence during a normal algorithm run (a run without breakpoints). Figure 3-10 illustrates such a sequence. The algorithm clock begins to toggle and the algorithm is put into reset for 4 algorithm clock cycles before triggering a new iteration of the algorithm.
When the algorithm is done, alg_done can either be set and held until the algorithm is reset or pulsed. Once asserted, one more algorithm clock cycle will be generated. At this point, the algorithm is done and no further algorithm clock pulses will be generated for this iteration. The user can then read the state of the algorithm block via the debug registers. The next time the algorithm is triggered by software, the reset sequence will start all over again. When there are no breakpoints, the activity of the step_flag signal is ignored. There are two resets, as follows:
core_rst for Core Services (used only in Core Services) controlled by Programmed Input/Output requests (PIOs) to the TIO ASIC (see Figure 1-4 and Figure 1-5)
algorithm reset (rst) in the Algorithm Block controlled by writing alg_go and alg_clr in CM_CONTROL
For more information on resets, see “Resets”.
This particular example (Figure 3-10) holds step_flag high, the method for clock based stepping.
An overview of the hardware algorithm design steps is presented in Figure 3-11.

The RASC FPGA gives the algorithm access to five banks of up to 40MB SRAM (see Figure 1-5). This section discusses the considerations for algorithm designers when deciding how to distribute input operands and parameters and output results among the available SRAM banks.
The primary recommendation for data distribution is to organize algorithm inputs and outputs on separate SRAM banks. In other words, if bank 0 is used for input data, it should not also be used for output data and vice versa (by splitting the SRAM into two logical halves, for example). The motivation for this guideline comes from the fact that when an algorithm accesses a particular bank's read or write port, it blocks access to the DMA engine that wants to unload finished results or load new operands.
To avoid multiple arbitration cycles that add to read and write latency when designing an algorithm, see “Arbitration”, that describes how arbitration changed in the RASC 2.1 release from prior releases.
In order for the hardware accelerated algorithm to run efficiently on large data sets, it is recommended to overlap data loading and unloading with algorithm execution. To do this successfully, the algorithm designer needs to start with an SRAM layout of algorithm operands and results that allows each bank to be simultaneously accessed by the algorithm for one direction (read or write) and a DMA engine for the other direction (write or read).
The Algorithm can implement two different forms of Debug Mode, based on convenience or the desired granularity of step size: clock cycle based stepping or variable (ad hoc) stepping. The differences between the two determine the step size, or how long the algorithm will run when triggered to step once. There are also implementation differences for the step size variants. Currently, only one type of debug mode is supported at a time.
Clock cycle based stepping means that the step size is one clock (clk) cycle. This method is easily implemented in RTL-based algorithms by tying the step_flag output (set_flag_out) to one (logic high). The step counter used by the debugger is 16 bits, so the maximum number of clock cycles that can be stepped in one debugger command is 2^16-1 = 65,535. An example of this mode is shown in Figure 3-12. This is for one alg_clk cycle. The figure shows rst asserted for four rising clk edges. Note that you can rely on reset (rst) being asserted for longer than one cycle.
Note that since the Algorithm Block cannot detect when clk has stopped, the effect of stepping is transparent to the Algorithm Block.
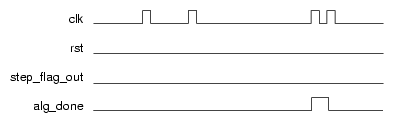
Another approach for implementing debugging is to assert step_flag at points of interest rather than every clock cycle, which makes the step size a variable number of clock cycles. One example of this method would be to use step_flag as an output of the last state of the FSM. Another example would be for the user to put in a “trigger” for when an internal counter or state machine reaches a specific value (with an indeterminate number of clock cycle steps in between). In this case, step_flag is tied to the trigger so that the algorithm can break at a designated point.
The ad hoc nature of this approach requires the algorithm to define and notify Core Services of step boundaries with the step_flag signal. The clk signal will not stop toggling during the same clock cycle that the step_flag signal is asserted; it will turn off on the following clock (clk)cycle. See the timing diagram in Figure 3-13.
The process of using a write port involves the following step (example given for SRAM<n> alone):
When the address, data and byte enables are valid for a write, assert mem_<n>_wr_cmd_vld (reoccurring phase)
Figure 3-14 shows single and back-to-back write commands.

The process of using a read port involves the following steps (example given for SRAM<n> alone):
When the address is valid for a read, assert mem_<n>_rd_cmd_vld (reoccurring phase). This step can be repeated while waiting for data (back-to-back burst reads). The algorithm can issue one quad-word (16 byte) read command every clk cycle per bank.
The read data will return on the bus mem_<n>_rd_data[127:0] several clock cycles later in the order it was requested (mem_<n>_rd_cmd_vld indicates that the read data is valid). The observed read latency from the algorithm's perspective will vary based on the clock period ratio between alg_clk and core_clk. Read latency is nominally 13 core_clk cycles; burst read commands are recommended for optimal read performance.
The algorithm should use the provided read data valid signal to determine when read data is valid and not attempt to count data cycles for expected latency.

Many applications targeted for hardware acceleration have large input and output data sets that will need to be segmented to fit subsets into the RASC brick's or RASC blade's external SRAM banks at any given time (a total of 40 MB per FPGA or 80 MB per blade) are available). Certain applications have large input data sets that have the same processing performed on subsets and only require that new input data be available in order to maintain continuous processing. These requirements bring up the notion of multibuffering of a large data set through an algorithm. Multibuffering data provides a continuous and parallel flow of data to and from the algorithm. Multibuffering provides the means to sequentially load data, execute, and unload a block of data in a loop one at a time.
In order for the hardware accelerated algorithm to run efficiently on large data sets, it is recommended to overlap data loading and unloading with algorithm execution. To do this successfully, start with an SRAM layout of algorithm operands and results that complies with the recommendations for memory distribution. The input and output data needs to be segmented into at least two segments per SRAM bank so that the Algorithm Block can execute on one segment while the next data segment is loaded by the Read DMA Engine and the previous output data segment is unloaded by the Write DMA Engine (ping-pong buffer effect). The SRAM bank can be segmented into any number of segments, as the algorithm and application designers best see fit.
algorithm iteration
One run of the algorithm; the operation that the algorithm performs between the time alg_rst is deasserted until the alg_done flag is asserted. Successive iterations require software to retrigger the algorithm.
segment / segment size
The amount of memory needed on a particular SRAM bank for an algorithm iteration, round up to the nearest power of 2. One segment could include multiple input operands or multiple output operands, with spaces of unused memory within the segment if desired. A segment does not include fixed parameters that are applied to multiple algorithm iterations.
A multibuffered segment must be at most 1/2 of the SRAM bank's size. The minimum segment size is 16KB (but not all 16KB need to be used). Different SRAM banks can have different segment sizes according to the sizes and number of operands / results that reside on a particular SRAM bank.
alg_mem_0_offset[23:14] and alg_mem_1_offset[23:14]
Inputs to the Algorithm Block that specify for each SRAM the starting address of the current data segment. When used, these inputs get mapped to the Algorithm Block's SRAM address bits [23:14] (byte aligned address). The actual number of bits that are used for the mapping is determined by the segment size. If the segment size is 16KB, all 10 bits are mapped to SRAM address bits [23:14]. If the segment size is 512 KB, only bits [23:19] are mapped to SRAM address bits [23:19]. If the segment size is 8MB, only bit [23] is mapped to SRAM address bit [23].
In order to support multibuffering, an algorithm should allow the upper bit(s) of its read and write SRAM addresses to be programmable via the alg_mem*_offset inputs. The offset inputs come from an internal FPGA register within the Core Services Block, accessible by the software layer. The offset inputs are 10 bits each, and can map to bits [23:14] of the corresponding SRAM address. Only the bits that correspond to the segment offset are used for a particular algorithm/application. For example, if the segment size is 32 KB, which leads to 512 segments in the 16MB bank, only the upper 9 of the 10 offset bits are used. Example Register Transfer Level (RTL) code for this configuration is shown below:
reg [23:15] mem0_rd_segment_addr;
reg [14:0] mem0_rd_laddr;
wire [23:0] mem0_rd_addr;
// Read pointer
always @(posedge clk)
begin
// Fixed upper address bits [23:15] per iteration
if (rst) mem0_rd_segment_addr <= alg_mem0_offset[23:15];
// Counter for lower address bits [14:0]
if (rst)
mem0_rd_laddr <= 15'h000;
else if (rd_advance_en)
mem0_rd_laddr <= mem0_rd_laddr + 15'h10;
end
assign mem0_rd_addr = {mem0_rd_segment_addr, mem0_rd_laddr};
|
The algorithm must define a legal segment size between the minimum and maximum allowable sizes, and only operate on and generate one segment worth of data per iteration.
Special extractor directives are required to pass information about the algorithm's data layout and multibuffering capabilities to the software layer. The software layer requires a declaration of the input and output data arrays on each SRAM bank, with attributes size, type, and buffer-ability defined. The declarations are provided as extractor directives, or comments in the Verilog or VHDL source code. The following example comments are used to declare two 16KB input data arrays located on SRAM 0, and one non-multibuffering input parameter array, also located on SRAM 0:
##Array name ## # of elements in array ## Bit width of element ## SRAM location ## Byte offset (within given SRAM) ## Direction ## Type ## Stream flag // extractor SRAM:input_a 2048 64 sram[0] 0x000000 in unsigned stream // extractor SRAM:input_b 2048 64 sram[0] 0x004000 in unsigned stream // extractor SRAM:param_i 512 64 sram[0] 0xffc000 in unsigned fixed |
| Note: In the code example above, stream is in the context of multibuffering. The stream data type is an historical anachronism and thus still appears in extractor directive code. |
For arrays that are defined as buffered, the byte offset provided in the extractor comments is used to establish the data placement within a particular segment. In the declaration, the byte offset is given at the lowest segment address. For fixed arrays, the byte offset is the absolute placement of the data within the SRAM.
Further details on extractor comments can be found in Chapter 7, “RASC Algorithm FPGA Implementation Guide”
Software uses configuration information derived from extractor directives to move the current active segment on each run of the algorithm. Software changes the values of alg_mem_0_offset[23:14] and alg_mem_1_offset[23:14] for each run of the algorithm and similarly moves the DMA engines' input and output memory regions based on the current active segment.
This section describes the ways that variable parameters can get passed to the algorithm. For the purposes of this document, a parameter is distinguished from the general input data in that it can be fixed over multiple runs of the algorithm and does not require reloading. It is assumed that input data changes more often than parameters.
The method used to pass variable parameters depends on the size and number of the required parameters. For a small number of 1-8 byte-sized parameters, the Algorithm Block can associate parameters with up to 64 Algorithm Defined Registers. The Algorithm Defined Registers are 64 optional registers that exist within the SSP memory mapped register region whose current values are inputs to the Algorithm Block (by default only the first eight of the following are defined: alg_def_reg<n>[63:0] where <n> is an integer 0-63). The Algorithm Block can assign reset (default) values for the parameters by tying the output signals alg_def_reg<n>_wr_data[63:0], and allow the host application to change them.
When an algorithm requires larger fixed parameters, portions of the SRAM banks can be used to hold the parameter data. This portion of the SRAM needs to be reserved for parameter data and kept unused by input data, so parameters need to be considered in the initial memory allocation decisions. Just as with small parameters, the mapping of parameter data to SRAM addresses is specified with extractor comments. The template and an example is provided below; further details are in the “Adding Extractor Directives to the Source Code” in Chapter 7. In the provided example, a 1024-element parameter matrix (8KB) is mapped to the upper 8KB of SRAM0, which starts at address 0xFFE000. The type is unsigned and the array is fixed, which denotes that it is a parameter array and not as variable as an input data array (the other option is “stream”).
// extractor SRAM:<parameter array name> <number of elements in array> <bit width of elements> <sram bank> <offset byte address into sram> in <data type of array> fixed // extractor SRAM:param_matrix0 1024 64 sram[0] 0xFFE000 in u fixed |
Another use of declaring a fixed array in one of the SRAMs could be for a dedicated scratch pad space. The only drawback to using SRAM memory for scratch pad space is that an algorithm normally writes and then reads back scratch pad data. This usage model violates the multibuffering rule requiring an algorithm to dedicating each SRAM bank for either inputs or outputs. If you have a free SRAM bank that you do not need for inputs or outputs, this violation can be avoided and the multibuffering model can be maintained. If you have a free SRAM that is not being used for anything else, then you do not even have to add an extractor directive. An extractor directive is necessary if the SRAM bank is being used for other purposes so that software does not overwrite your scratch pad space. An extractor directive is also necessary to be able to access the scratch pad space from the debugger (reads and writes), so in general, an extractor directive is recommended.
Note that if you violate the multibuffering model for SRAM direction allocation, data will not be corrupted but the benefit of multibuffering will not occur because data transfer and algorithm execution cannot be overlapped. A template and an example is provided below for writing an extractor comment for a scratch pad space is, as follows:
// extractor SRAM:<scratch_pad_array_name>
<number of elements in array>
<bit width of elements>
<sram bank>
<offset byte address into sram>
inout
<data type of array>
<signed / unsigned>
fixed
// extractor SRAM:scratch1 1024 64 sram[2] 0x000000 inout u fixed
|
These guidelines are suggestions for achieving 200 MHz timing, when possible (not including floating point operations or use of multipliers).
Flop all outputs of the algorithm block, especially critical outputs, such as step_flag.
Flop and replicate the rst input if needed to distribute it as a high fanout signal.
Flop the input strm_in_<n>_data_vld data, mem_<n>_rd_data_vld and mem_<n>_rd_data before performing combinatorial logic on the data or data valid signals.
The general rule to abide by when trying to code a design that passes timing at 200 MHz is this: do not give PAR (the place and route tool) any tough decisions on placement where it would be difficult to find a good location. If a critical signal loads logic in multiple blocks, replicate it so that PAR does not have to try to optimize placement of the driving flop relative to the various loading blocks. You may have to add synthesis directives to prevent the synthesis tool from “optimizing out” your manually replicated flops. As far as possible, do not have a flop drive combinational logic in one block that then loads additional combinational logic in another block (such as Core Services), unless they can be physically grouped to adjacent locations, or in the worst case, minimize the total number of logic levels.
This section shows how to make signals internal to the Algorithm Block viewable by the FPGA-enabled GNU Debugger (GDB) software. The Algorithm Block has up to 64 debugger output ports, each 64-bits wide. In order to make internal signals visible, the algorithm code should connect signals of interest to these outputs ports. To ease the timing issues on paths coming from the Algorithm Block, it is suggested to feed reregistered outputs to the debug outputs. Several examples are shown below:
assign debug0 = 64'h0000_000c_0000_0003; //[63:32] alg#, [31:0] rev# |
In the above example, the outputs are tied, so it is not important to register the outputs.
always @(posedge clk)
debug1 <= {32'h0, running_pop_count};
|
Since the intermediate value running_pop_count is also loaded by internal Algorithm Block logic, it is recommended to flop debug register 1 rather than use a wire connection. This helps isolate the loads of running_pop_count and reduce the number of constraints on the place and route program.
Besides connections to the debug port, the algorithm has to contain extractor comments that will pass the debug information to the software layer. Debug outputs use the REG_OUT type of extractor comment. The extractor comment tells the software layer what the mapping will be for internal signals to the corresponding debug address location. Examples are as follows:
// extractor REG_OUT:rev_id 32 u debug_port[0][31:0] |
and
// extractor REG_OUT:running_pop_count 32 u debug_port[1][31:0] |
The general format is:
REG_OUT:<signal name> <signal bit width> <type:unsigned/signed> <debug port connection>[<bit range>] |
This section discusses additional details, including locations of the Algorithm Block in the design hierarchy, and global FPGA logic, such as clocks and resets. It covers the following topics:
Figure 3-17 shows the instance hierarchy of the RASC FPGA design. The top-of-chip is a wrapper module called acs_top. The instances in the top level include I/O buffer wrappers, clock resources wrappers, and the two major subdivisions of the logic design: acs_core, the pre-synthesized Core Services logic, and the user_space_wrapper, the top-level wrapper for the user/algorithm logic. As the algorithm application writer, you should begin the algorithm design using alg_block_top as the top level of the algorithm. The other instances within user_space_wrapper are small parts of Core Services resources that are left to be resynthesized based on their use and fanout within the algorithm logic. These include reset fanout logic and the debug port multiplexor.
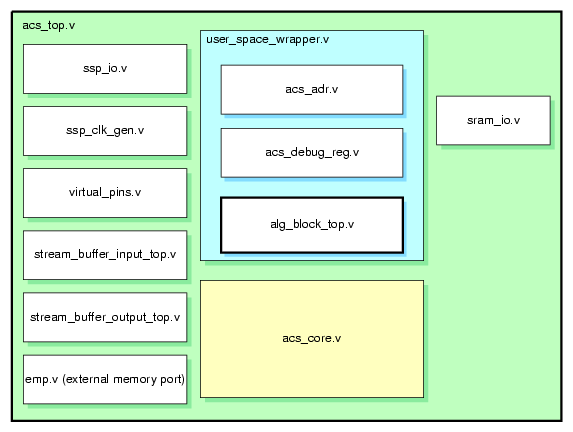
The Algorithm / Core Services interface as defined in the section entitled “Algorithm Interfaces ”, consist of the input and output signals defined for the module alg_block_top.
This section describes the clock domains within the RASC Field Programmable Gate Array (FPGA), with a focus on the algorithm clock domain used by the Algorithm Block logic. There are two major domains: core clock and algorithm clock. However, the two domains are not completely asynchronous. They may either both be 200 MHz and phase aligned, or the algorithm clock can have a 50, 66, or 100 MHz and the clocks will be phase / edge-aligned (that is, a rising edge of the algorithm clock will correspond to a rising edge of the core clock).
This section covers the following topics:
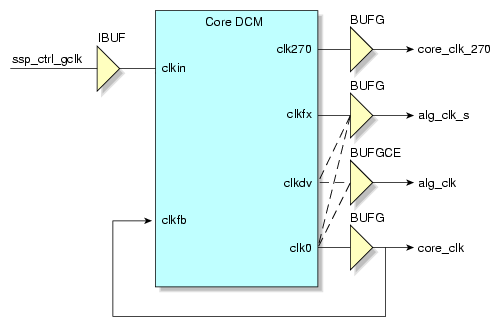
The core clock has a fixed clock rate of 200 MHz. It is the main clock used within the Core Services Block. It is derived from the input control clock on the Scalable System Port (SSP) interface. The input clock is used as the clock input to the core clock digital clock manager (DCM) module. The clk0 output of the DCM is driven onto a low-skew global clock buffer (BUFG) and from there is routed to core_clk domain registers as well as the feedback of the DCM for fine phase adjustments. In the place and route report, this clock is labelled core_clk.
The algorithm clock rate is selectable through the use of macro definitions. Speeds of 50, 66, 100, and 200 MHz can be selected. For speeds slower than 200 MHz, the DCM clock divider in the Xilinx Virtex 4 FPGA is used to create the alg_block_top module input called clk, the specified clock signal. Figure 3-18 shows a block diagram of the logic used to create the clock signals. The RASC 2.20 release supports a supplemental algorithm clock. The additional clock signal is alg_clk_s that can be driven by one of the following outputs of DCM: clk0, clkdv, or clkfx. For more information, see “Supplemental Algorithm Clock”.
Macro definitions are used to select between the clk0 and clkdv outputs of the DCM to drive the BUFGCE clock buffer, which in turn drives the clk signal in the Algorithm Block via the alg_clk signal.
The signal alg_clk_enable (not shown) generated by Core Services gates alg_clk. By gating the clock, the signal toggles only when the Algorithm Block is active. In the place and route clock report, this clock is labelled alg_clk.
When clkdv is used to drive the algorithm clock, the phase relationship between the core clock and the algorithm clock is determined by the Virtex 4 parameter CLKOUT_PHASE, which specifies the phase relationship between the DCM outputs of the same DCM. For Virtex 4 FPGAs, this parameters is specified as +/- 140 ps. Although the Xilinx timing tools do not take the CLKOUT_PHASE into account directly during analysis, an additional 140 ps has been added as input clock jitter to force the tools to correctly check paths crossing the core_clk and alg_clk domains. Any phase difference that is derived from the varying routes between the DCM outputs and the BUFG / BUFGCE elements as well as the clock tree fanouts are automatically considered by the Xilinx timing tools.
Core clock domain signals in the Core Services Block that communicate with the Algorithm Block, which is entirely in the alg_clk domain, have been designed to transition on the rising edge of alg_clk, even when alg_clk is run slower than the rate of core_clk.
Besides the core clock domain, which is equivalent to the Scalable System Port (SSP) control group domain, there are four data group clock domains within the SSP source synchronous receiver and transmitter logic. These four groups have a determined phase relationship between one another: each group is separated by a nominal 250 ps shift to reduce simultaneous switching noise on the SSP interface. In the place and route clock report, these clocks are labelled int_grp1_clk - int_grp4_clk.
The QDR-II SRAM module interfaces, a part of Core Services, uses five additional clock domains: one receive clock for each external SRAM (for a total of five, one for each physical SRAM component), and one common data transmit clock, which is a quarter clock cycle early relative to the core_clk. In the place and route clock report, these clocks are labelled bank0_sram_rcv_clk, bank1_sram_rcv_clk, bank2_sram_rcv_clk, bank3_sram_rcv_clk, and core_clk270.
The RASC 2.20 software release supports a new supplemental clock feature on the RC100 blade. For more information, see “Supplemental Algorithm Clock”.
This section describes the hardware resets in the RASC Field Programmable Gate Array. The primary reset input to the FPGA is the CM_RESET signal on the SSP port. It is used as both a clock reset and as the basis of a full-chip control logic reset. When used as a clock reset, it is used as an asynchronous reset to the DCMs in the design. A full-chip logic reset is generated based on the assertion of CM_RESET or the de-assertion of any of the DCM locked signals. There is a circuit in Core Services that generates a synchronous core_rst signal, synchronous to the core clock domain. This reset is used throughout the control logic in Core Services.
The Algorithm Block receives a different reset generated by the Core Services' Algorithm Controller sub-module. The Algorithm Block receives a reset that is synchronous to the algorithm clock. After a full-chip reset, the Algorithm Block's reset input will remain asserted even after core_rst is removed. When the algorithm is started by software for the first time, the algorithm reset is removed. This is to allow for debug testing of internal signals after the algorithm completes. When software restarts the algorithm for another run (by setting the ALG_GO bit in the CM_CONTROL Register), the Algorithm Block will be held in reset for a total of 4 algorithm clock cycles, and then the algorithm reset will be released to allow the Algorithm Block to execute.
To summarize: the Algorithm Block is held in reset until its first use. Each time the algorithm is triggered to execute, the Algorithm Block will be held in reset for 4 clock cycles.
This section describes the parameters to be specified by the algorithm designer in order to set the clock rate of the algorithm clock and to enable access to specific SRAM banks.
These synthesis-time parameters are specified in a Verilog include file called alg.h and are used by the top-level of design hierarchy. An example of this header file can be found in $RASC/example/alg_simple_v/alg.h.
The primary algorithm clock rate can be set at 50, 66, 100, or 200 MHz.
The following is a portion from the above example include file that selects the clock speed. This shows the four macros used to specify an algorithm clock speed.
//////////////////////////////////////////// // Specify clock speed of algorithm // //////////////////////////////////////////// // Only one of the below four should be uncommented // For 200 MHz `define alg_clk_5ns // For 100 MHz // `define alg_clk_10ns // For 66 MHz // `define alg_clk_15ns // For 50 MHz // `define alg_clk_20ns |
One and only one of the above four macros must be defined. Here the macro to set the algorithm clock rate to 200 MHz is defined and uncommented whereas the other macros are left undefined.
In order for the Algorithm Block to have access to a given SRAM port, the corresponding macro must be defined in alg.h.
The following portion from the include file enables access to SRAM ports and shows one particular memory configuration. You can also use the SGI RASC Algorithm Configuration Wizard to configure memory, as described in “Memory Configuration” in Chapter 8.
//////////////////////////////////////////// // Specify SRAM ports for algorithm use // //////////////////////////////////////////// `define alg_uses_sram0_rd //`define alg_uses_sram0_wr //`define alg_uses_sram1_rd `define alg_uses_sram1_wr |
All, some, or none of these macros can be defined. In this example, the read port for SRAM bank 0 and the write port for SRAM bank 1 are enabled, while the write port for SRAM bank 0 and the read port for SRAM bank 1 cannot be used by the Algorithm Block.
The DMA engines and the Algorithm block can operate concurrently, but the algorithm must deal with arbitration. For more information on arbitration, see “Arbitration”.
The system memory configuration is definded in the Makefile.local file, as follows:
## Specify memory configuration # Configuration no memory interfaces #MEM_CFG_NONE=1 # Configuration 0: max 2x double-width SRAM QDR2 + # 1x single-width SRAM QDR MEM_CFG_0=1 # Comment out unused memories below USE_MEM_0=1 USE_MEM_1=1 #USE_MEM_2=1 # Configuration 1: max 5x single-width SRAM QDR2 #MEM_CFG_1=1 # Comment out unused memories below #USE_MEM_0=1 #USE_MEM_1=1 #USE_MEM_2=1 #USE_MEM_3=1 #USE_MEM_4=1 # Configuration 2: max 5x double-width DRAM DDR2 #MEM_CFG_2=1 # Comment out unused memories below #USE_MEM_0=1 #USE_MEM_1=1 #USE_MEM_2=1 #USE_MEM_3=1 #USE_MEM_4=1 |
The macro for USE_MEM_2 in alg.h needs to be uncommented, as in:
// Comment out unused memories below `define USE_MEM_0 `define USE_MEM_1 `define USE_MEM_2 |
The first two define statements, of course, can be commented out.
The RASC 2.20 software release supports a new supplemental clock feature on the RC100 blade.
| Note: You can use this feature running RASC 2.20 if you update the design/clk_gen/ssp_clk_gen.v file. |
The supplemental clock feature provides an application algorithm a second independent clock. It provides a finer granularity in choosing the algorithm clock frequency, relative to the four provided by the primary clock (see “FPGA Clock Domains”). It also allows you to implement an algorithm where sections of the algorithm are clocked at different rates. Regardless of the algorithm clocking frequency choices you make, the core_services block is clocked at a 200 MHz rate. The phase relationship of the supplemental clock to the primary clock is dependent upon the core clock digital clock manager (DCM) module of the Xilinx FPGA (see “Core Clock Domain”).
It is important to understand that you, as the algorithm designer, are responsible for assuring reliable data transfer across any clock domain boundaries created by the use of the supplemental clock. Potential issues involved and possible solutions are discussed in Xilinx documents such as fifo_generator_ds317.pdf and Chapter 4, “Block RAM” of the Virtex-4 User Guide available at http://www.xilinx.com/ .
The supplemental clock is enabled and controlled by define statements in the alg.h file, as follows:
Add the supplemental clock ports to modules.
`define USE_ALG_CLK_S
This adds the alg_block_top module input called clk_s to which you can connect sections or all of the algorithm block.
This also adds the clk_s port to the alg_block_top instantiation in the user_space_wrapper module. In the user_space_wrapper module, this clk_s port is connected to the alg_clk_s input port of user_space_wrapper.
Select the supplemental clock frequency. See “Special Case Frequencies” and “General Case Frequencies”.
Some frequency selections are treated as special cases. These are the cases where the selected frequency has a simple relationship to the 200 MHz core_services clock frequency and does not use the general frequency synthesis capability of the DCM. These are the supported special cases. The special cases only use the CLK0 and CLKDV outputs of the DCM for the primary and supplemental clocks.
Case #1 - Primary clock = 200 MHz, supplemental clock = 100 MHz
`define alg_clk_5ns |
Do not define alg_clk_s_5ns
Do not define alg_clk_s_fx
Case #2 - Primary clock = 100 MHz, supplemental clock = 200 MHz
`define alg_clk_s_5ns `define alg_clk_10ns |
Do not define alg_clk_s_fx
Case # 3 - Primary clock = 66 MHz, supplemental clock = 200 MHz
`define alg_clk_s_5ns `define alg_clk_15ns |
Do not define alg_clk_s_fx
Case # 4 - Primary clock = 50 MHz, supplemental clock = 200 MHz
`define alg_clk_s_5ns `define alg_clk_20ns |
Do not define alg_clk_s_fx
There are a few uninteresting cases when none of the supplemental clock parameters are defined and the primary clock is not 200 MHz, as follows:
If alg_clk_s_5ns is not defined,
and alg_clk_s_fx is not defined,
and alg_clk_10ns, alg_clk_15ns or alg_clk_20ns is defined
In these cases, the primary and supplemental clocks are the same frequency, therefore, the supplemental clock offers no benefits.
This mode provides a large selection of discrete supplemental clock frequencies. This mode uses DCM frequency synthesis, so the supplemental clock frequency is essentially independent of the core_services clock frequency. In this mode, the supplemental clock is connected to the DCM clkfx output.
This mode is enabled when the alg.h file has the following defines:
`define alg_clk_s_fx |
Do not define alg_clk_s_5ns
The synthesized frequency is controlled by two additional defines in alg.h. See the Xilinx Virtex-4 datasheet ds302.pdf for restrictions upon the frequency synthesis capability. They are listed under the "DCM and PMCD Switching Characteristics" and "Output Clock Phase Alignment" sections of this document (Tables 42, 43 and 48 in a recent revision).
The synthesized frequency is determined by applying multiplication and division factors to the 200 MHz core_services clock. Each factor has its own define. The following is an example for synthesizing a 300 MHz supplemental clock:
`define ALG_CLK_S_MULT 3 `define ALG_CLK_S_DIV 2 |
For information on the algorithm primary clock and how to set it, see “Setting the Primary Algorithm Clock Speed”.
This section provides a reference on how to simulate the Algorithm using the provided SSP Stub, sample test bench, and VCS simulator. It covers the following topics:
The Sample Test Bench (also called sample_tb) is a basic simulation environment for users to do sandbox testing of their algorithm code. The Sample Test Bench is provided as an optional intermediate step between writing an algorithm and loading the algorithm into RASC hardware. It is intended to help insure that the algorithm will function on a basic level (for example, a single algorithm iteration) prior to debugging a bitstream in hardware.
The sample test bench is designed for use with VCS. For use with other simulators, the user should modify the sample test bench along with associated scripts and makefiles.
A primary component of the sample test bench, the SSP Stub, consists predominantly of Verilog modules, although it also includes PLI calls to functions written in C code. The stub is instantiated in a sample Verilog test bench along with the Algorithm FPGA. The files for this test bench are in the directory, $RASC/dv/sample_tb/. In this directory you will find the following Verilog modules and other files:
top.v: The top level of the sample test bench containing the Algorithm FPGA design (Core Services and the user's algorithm), SSP Stub, SRAM simulation models, and clock generator.
ssp_stub.v: Top level Verilog of the SSP Stub which passes signals to and from conversion modules. More information on submodules, PLI calls, and C functions that comprise the SSP Stub can be found in the “SSP Stub User's Guide” section of this document.
init_sram0_good_parity.dat, init_sram1_good_parity.dat, init_sram2_good_parity.dat, init_sram3_good_parity.dat, init_sram4_good_parity.dat: These SRAM initialization files contain data which is automatically loaded into the respective SRAM simulation models at the beginning of simulation. The data is in a format which the SRAM simulation model uses with the ECC bits embedded with the data. These default files can be overridden by the user on the command line at runtime.
final_sram0.dat, final_sram1.dat, final_sram2.dat, final_sram3.dat, final_sram4.dat: These files contain data extracted from the respective SRAM simulation models at the end of simulation. These default files can be overridden by the user on the command line at runtime.
timescale.v: This file contains the Verilog timescale of each of the components of the SSP Stub, as well as the algorithm FPGA design files. It is required that the algorithm being simulated makes use of the same timescale as the rest of the design.
In order to use the sample test bench, your VCS environment variables should be set up as follows:
### Environment Variables for VCS ### setenv VCS_HOME <your_vcs_install_directory> setenv VCSPLIDIR $VCS_HOME/<your_vcs_pli_directory> setenv PATH $PATH\:$VCS_HOME/bin |
Compiling the sample test bench is done using the Makefile provided. In order to compile the sample testbench including the SSP Stub and the algorithm Core Services logic, an algorithm must be specified (See the following note).
| Note: The Makefile in the sample_tb directory uses the $ALG_DIR environment variable. This defaults to $RASC/examples though it can be modified by the user. The design files of the algorithm you specify must be in a directory under the $ALG_DIR path. |
If the algorithm is written in VDHL, set the HDL_LANG environment to vhdl, as follows:
% setenv HDL_LANG vhdl |
Otherwise, the algorithm is considered to be written in Verilog.
The algorithm you are building is specified on the command line. To compile the design with your algorithm, change directory to $RASC/dv/sample_tb and enter:
% make ALG=<your_algorithm> |
where <your_algorithm> is the directory name where the algorithm design files are. When no algorithm is specified, the default is ALG=alg_simple_v.
To remove older compiled copies of the testbench, type:
% make clean |
To run a diagnostic on your algorithm, call the Makefile in the sample_tb directory using the “run” target and specifying which diag to run. The following is the usage and options of the “run” target:
% make run DIAG=diag_filename ALG=your_agorithm SRAM0_IN=sram0_input_file SRAM1_IN=sram1_input_file SRAM2_IN=sram2_input_file SRAM3_IN=sram3_input_file SRAM4_IN=sram4_input_file SRAM0_OUT=sram0_output_file SRAM1_OUT=sram1_output_file SRAM2_OUT=sram2_output_file SRAM3_OUT=sram3_output_file SRAM4_OUT=sram4_output_file |
The diag_file specifies the diagnostic to be run and should be relative to the current directory. Again, the algorithm must be specified using the ALG=your_algorithm command line option. If none is specified, the runtime command uses same default as above (ALG=alg_simple_v). Specifying ALG this way allows the user to reuse the same diagnostic for multiple algorithms. The contents of each SRAM at the end of simulation will be dumped into .dat files that can be user-specified. If they are not specified, they default to:
init_sram0_good_parity.dat init_sram1_good_parity.dat init_sram2_good_parity.dat init_sram3_good_parity.dat init_sram4_good_parity.dat final_sram0.dat final_sram1.dat final_sram2.dat final_sram3.dat final_sram4.dat |
Note that there are five input and five output SRAM data files while the design is implemented for two logical SRAMs. Each of the logical SRAMs 0-4 are implemented as two separate physical SRAMs in the sample testbench.
The sram0* and sram1* files correspond to the first logical SRAM while sram2*, sram3*, correspond to the second logical SRAM. The sram4* files correspond to the 5th physical SRAM.
By specifying the SRAM input and output files the user can skip the DMA process for quick verification of the algorithm. This shortens the diagnostic run time, makes for less complex diagnostics, and allows the user to ignore core services as it has already been verified by SGI. The option of utilizing the DMA engines in simulation is included for completeness but should not be necessary for typical algorithm verification.
The association of SRAM0_IN and SRAM0_OUT with physical memory is, as follows:
mem0[127:64] -> qdr_sram_bank1.SMEM -> init_sram1_*.dat, final_sram1.dat mem0[63:0 ] -> qdr_sram_bank0.SMEM -> init_sram0_*.dat, final_sram0.dat mem1[127:64] -> qdr_sram_bank3.SMEM -> init_sram3_*.dat, final_sram3.dat mem1[63:0 ] -> qdr_sram_bank4.SMEM -> init_sram2_*.dat, final_sram2.dat mem2[63:0 ] -> qdr_sram_bank2.SMEM -> init_sram4_*.dat, final_sram4.dat |
As the diagnostic runs, it will output status to the screen and to an output file named <diag_filename>.<your_algorithm>.run.log. When the stub receives an unexpected packet, it will output the following information in order: the command for the next expected packet, SSP fields of the expected packet, the command translation (if one exists) for the received packet, and the SSP fields of the received packet. This log file will appear in the same directory in which that the diagnostic is located.
Table 3-7 shows a summary of the algorithms, diagnostics, and commands provided with the sample testbench.
Table 3-7. Sample Testbench Algorithms and Commands
Algorithm Name | Diagnostic | Compile and Run Commands |
|---|---|---|
alg_simple_v | diags/alg_simple_v | make ALG=alg_simple_v make run DIAG=diags/alg_simple_v ALG=alg_simple_v |
alg_data_flow_v | diags/alg_data_flow_v | make ALG=alg_data_flow_v make run DIAG=diags/alg_data_flow_v ALG=alg_data_flow_v |
Each time a diagnostic is run, a file named vcdplus.vpd is generated in the sample_tb directory. This file can be input to Virsim for viewing the waveform. Since this file is generally large, it is overwritten for each diagnostic run. To save the waveform for a given diagnostic, copy the corresponding vcdplus.vpd file to a new name.
To view the waveform saved in the vcdplus.vpd file, use the following command:
% vcs -RPP vcdplus.vpd |
A sample configuration file sample_tb/basic.cfg is provided for use when viewing waveforms in Virsim. It contains a limited number of relevant signals on the SSP interface, SRAM interfaces, and inside the design. Figure 3-19 shows a sample vcdplus.vpd waveform in Virsim.

The SSP Stub retrieves instructions through a text input file, the diagnostic. The SSP Stub parses this file at each semicolon to extract commands that the Stub executes. Many of the allowed commands in a diagnostic correspond to SSP packet types. There are other commands that the SSP Stub supports for diagnostic writing and debugging. The primary components of the diagnostic file are: packet commands, debugging commands, and comments.
It is important to note that most SSP packets come in pairs: a request and a response. For these types of packets, the request command and response command must be listed sequentially in a diagnostic. This method of keeping requests and response paired is used by the stub to associate request and response packets with the corresponding transaction number (TNUM). For more information on SSP packet types, see the Scalable System Port Specification. Also, when running the DMA engines, all transactions related to that sequence of events should be grouped together. See Appendix B, “SSP Stub User's Guide” for more details on diagnostic writing and using the SSP stub.
The code listed below comprises a diagnostic that exercises the basic functionality of the algorithm FPGA outlined in the following steps:
Initializes the algorithm FPGA Core Services (primarily MMR Writes)
Executes DMA Reads to send data to the FPGA (stored in SRAM)
Starts the Algorithm (d = a & b | c) and polls the memory mapped registers (MMRs) to see when the Algorithm is done
Executes DMA Writes to retrieve the Algorithm's results
Checks the error status in the MMRs to verify that no errors were flagged.
The example diagnostic provided below is intended as a template that may be edited to match the user's algorithm.
####### Initialization packets. #######
# Arm regs by setting the REARM_STAT_REGS bit in the CM_CONTROL reg
snd_wr_req ( PIO, DW, ANY, 0x00000000000020, 0x0000000600f00003 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# Clear the CM_ERROR_STATUS register by writing all zeroes.
snd_wr_req ( PIO, DW, 3, 0x00000000000060, 0x0000000000000000 );
rcv_wr_rsp ( PIO, DW, 3, 0);
# Enable CM_ERROR_DETAIL_* regs by writing all zeroes to CM_ERROR_DETAIL_1.
snd_wr_req ( PIO, DW, ANY, 0x00000000000010, 0x0000000000000000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# Enable desired interrupt notification in the CM_ERROR_INTERRUPT_ENABLE
register.
snd_wr_req ( PIO, DW, 4, 0x00000000000070, 0xFFFFFFFFFFFFFFFF );
rcv_wr_rsp ( PIO, DW, 4, 0 );
# Set up the Interrupt Destination Register.
snd_wr_req ( PIO, DW, ANY, 0x00000000000038, 0x0000000000000000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
print "\n\nWait for SRAM bank calibration to complete.\n\n";
# Poll CM_STATUS for bits 51, 57, 58, 59, & 63.
poll (0x8, 63, 300);
print "\n\n*******Initialization finished\n\n";
####### Configure DMA Engines and Algorithm. #######
####### Configure the Read DMA Engine Registers. #######
print "\n\n*******Configure Read DMA Engine. Tell it to fill 32 cache lines
of data.\n\n";
# RD_DMA_CTRL register.
snd_wr_req ( PIO, DW, ANY, 0x00000000000110, 0x0000000000100020 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# RD DMA addresses.
snd_wr_req ( PIO, DW, ANY, 0x00000000000100, 0x0000000000100000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
snd_wr_req ( PIO, DW, ANY, 0x00000000000108, 0x0000000000000000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# RD AMO address.
snd_wr_req ( PIO, DW, ANY, 0x00000000000118, 0x0000000000000000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# RD_DMA_DEST_INT
snd_wr_req ( PIO, DW, ANY, 0x00000000000120, 0x0000000200002000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
####### Configure the Write DMA Engine Registers. #######
print "\n\n*******Configure Write DMA Engine.\n\n";
# Write to the WR_DMA_CTRL register.
snd_wr_req ( PIO, DW, ANY, 0x00000000000210, 0x0000000000100020 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# WR_DMA_SYS_ADDR
snd_wr_req ( PIO, DW, ANY, 0x00000000000200, 0x0000000000100000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# WR_DMA_LOC_ADDR
snd_wr_req ( PIO, DW, ANY, 0x00000000000208, 0x0000000000000000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# WR_DMA_AMO_DEST
snd_wr_req ( PIO, DW, ANY, 0x00000000000218, 0x0000000000000000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# WR_DMA_INT_DEST
snd_wr_req ( PIO, DW, ANY, 0x00000000000220, 0x0000000400004000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
####### Configure the Algorithm Registers. #######
print "\n\n*******Configure Algorithm Registers\n\n";
snd_wr_req ( PIO, DW, ANY, 0x00000000000300, 0x0000000000000000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
snd_wr_req ( PIO, DW, ANY, 0x00000000000308, 0x0000000600006000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
####### Start Read DMA Engine for Read DMA 1 #######
print "\n\n*******Start Read DMA Engine for SRAM0\n\n";
# Set Bit 36 of the CM_CONTROL Reg to 1.
snd_wr_req ( PIO, DW, ANY, 0x00000000000020, 0x0000001400f00003 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# 1 of 32
rcv_rd_req ( MEM, FCL, ANY, 0x00000000100000 );
snd_rd_rsp ( MEM, FCL, ANY, 0, 0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF );
# Other Read DMA Transactions omitted here
# 32 of 32
rcv_rd_req ( MEM, FCL, ANY, 0x00000000100F80 );
snd_rd_rsp ( MEM, FCL, ANY, 0, 0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF,
0xDEADBEEFDEADBEEF, 0xDEADBEEFDEADBEEF );
print "\n\n*******Polling for DMA RD-SRAM0 done (bit 42 of CM_STATUS).\n\n";
poll (0x8, 42, 20);
print "\n\n*******Done storing data in SRAM 0.\n\n";
####### Reconfigure DMA Engine for Read DMA 2 #######
# RD_DMA_SYS_ADDR
snd_wr_req ( PIO, DW, ANY, 0x00000000000100, 0x0000000000100000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# RD_DMA_LOC_ADDR
snd_wr_req ( PIO, DW, ANY, 0x00000000000108, 0x0000000000200000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
####### Start Read DMA Engine for Read DMA 2 #######
print "\n\n*******Start Read DMA Engine for SRAM1\n\n";
# Set Bit 36 of the CM_CONTROL Reg to 1.
snd_wr_req ( PIO, DW, ANY, 0x00000000000020, 0x0000001400f00003 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# 1 of 32
rcv_rd_req ( MEM, FCL, ANY, 0x00000000100000 );
snd_rd_rsp ( MEM, FCL, ANY, 0, 0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0 );
# Other Read DMA Transactions omitted here
# 32 of 32
rcv_rd_req ( MEM, FCL, ANY, 0x00000000100F80 );
snd_rd_rsp ( MEM, FCL, ANY, 0, 0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0,
0xF0F0F0F0F0F0F0F0, 0xF0F0F0F0F0F0F0F0 );
print "\n\n*******Polling for DMA RD-SRAM1 done (bit 42 of CM_STATUS).\n\n";
poll (0x8, 42, 200);
print "\n\n*******Done storing data in SRAM 1.\n\n";
####### Reconfigure DMA Engine for Read DMA 3 #######
# RD DMA addresses.
snd_wr_req ( PIO, DW, ANY, 0x00000000000100, 0x0000000000100000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
snd_wr_req ( PIO, DW, ANY, 0x00000000000108, 0x0000000000400000 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
####### Start Read DMA Engine for Read DMA 3 #######
print "\n\n*******Start Read DMA Engine for SRAM2\n\n";
# Set Bit 36 of the CM_CONTROL Reg to 1.
snd_wr_req ( PIO, DW, ANY, 0x00000000000020, 0x0000001400f00003 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# 1 of 32
rcv_rd_req ( MEM, FCL, ANY, 0x00000000100000 );
snd_rd_rsp ( MEM, FCL, ANY, 0, 0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C );
# Other Read DMA Transactions omitted here
# 32 of 32
rcv_rd_req ( MEM, FCL, ANY, 0x00000000100F80 );
snd_rd_rsp ( MEM, FCL, ANY, 0, 0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C,
0x0C0C0C0C0C0C0C0C, 0x0C0C0C0C0C0C0C0C );
print "\n\n*******Polling for DMA RD-SRAM2 done (bit 42 of CM_STATUS).\n\n";
poll (0x8, 42, 200);
print "\n\n*******Done storing data in SRAM 2.\n\n";
####### Start the Algorithm #######
# Set bit 38 of CM Control Register to 1 to start algorithm.
snd_wr_req ( PIO, DW, ANY, 0x00000000000020, 0x0000004400f00003 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
print "\n\n*******Started Algorithm.\n\n";
# Poll for ALG_DONE bit in CM_STATUS.
poll ( 0x8, 48, 2000);
print "\n\n*******Algorithm Finished.\n\n";
####### Start Write DMA Engine. #######
# Set bit 37 of CM Control Register to 1 to start Write DMA Engine.
snd_wr_req ( PIO, DW, ANY, 0x00000000000020, 0x0000002400f00003 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
print "\n\n*******Started Write DMA Engine.\n\n";
# 1 of 32
rcv_wr_req ( MEM, FCL, ANY, 0x00000000100000, 0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC );
snd_wr_rsp ( MEM, FCL, ANY, 0 );
# Other Write DMA Transactions omitted here
# 32 of 32
rcv_wr_req ( MEM, FCL, ANY, 0x00000000100F80, 0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC,
0xDCACBCECDCACBCEC,0xDCACBCECDCACBCEC );
snd_wr_rsp ( MEM, FCL, ANY, 0 );
print "\n\n*******Polling for DMA WR-SRAM0 done (bit 45 of CM_STATUS).\n\n";
poll (0x8, 45, 200);
print "\n\n*******Done retrieving data from SRAM 0.\n\n";
####### Finish Up ######
# dma_clear(). Set bits 39, 40, and 41 to 1 in CM_CONTROL.
snd_wr_req ( PIO, DW, ANY, 0x00000000000020, 0x0000038400f00003 );
rcv_wr_rsp ( PIO, DW, ANY, 0 );
# finalcheck_ccc() Check CACHE_RD_DMA_FSM.
snd_rd_req ( PIO, DW, ANY, 0x00000000000130 );
rcv_rd_rsp ( PIO, DW, ANY, 0, 0x0000000000400000 );
print "Reading the Error Status Register to insure no errors were
logged.\n";
snd_rd_req ( PIO, DW, ANY, 0x00000000000060 );
rcv_rd_rsp ( PIO, DW, ANY, 0, 0x0000000000000000 );
|
Various constants and definitions for the sample test bench are contained within the following files:
ssp_defines.h (internal stub variables)
user_const.h (user modifiable)
Table 3-8 lists the files in the sample_tb directory with their function and calls dependencies.
Table 3-8. Files in the sample_tb directory
File | Functions | Dependent On |
|---|---|---|
start_ssp.c | start_ssp() | queue_pkt.h, setup_pkt.h, send_rcv_flits.h |
send_rcv_flits.h | send_rcv_flits(), send_flit(), rcv_flit(),snd_poll(), rcv_poll(), finish_ssp() | setup_pkt.h, process_pkt.h, get_fields.h, snd_rcv_fns.h |
queue_pkt.h | queue_pkt(string), q_string_it(token, pkt_string),strtok_checked(s1, s2) | -- |
setup_pkt.h | setup_pkt(snd_rcv) | snd_rcv_fns.h |
snd_rcv_fns.h | snd_wr_req(pio_mem_n, size, tnum, addr, data, pkt), snd_rd_req(pio_mem_n, size, tnum, addr, pkt), snd_wr_rsp(pio_mem_n, size, tnum, error, pkt), snd_rd_rsp(pio_mem_n, size, tnum, error, data), snd_amo_rsp(tnum, error, pkt), inv_flush(tnum, pkt), rcv_wr_rsp(pio_mem_n, size, tnum, error, pkt), rcv_rd_rsp(pio_mem_n, size, tnum, error, data, pkt), rcv_wr_req(pio_mem_n, size, tnum, addr, data, pkt), rcv_rd_req(pio_mem_n, size, tnum, addr, pkt),rcv_amo_req(tnum, addr, data, pkt) | construct_pkt.h |
construct_pkt.h | construct_pkt(type, tnum, address, data, error, pkt, to_from_n), pkt_size(type) | make_command.h |
make_command.h | make_command(type, tnum, error, to_from_n) | -- |
get_fields.h | get_fields(type), f_string_it(token) | -- |
process_pkt.h | process_pkt(type) | -- |
The sample test bench includes utilities that help in generating and interpreting diagnostic data. To compile these files into executables, run the following command:
% gcc -c file_name -o executable name |
The utilities provided include the following:
convert_sram_to_dw.c
This program takes a standard SRAM input/output file (e.g. final_sram0.dat), and converts it to a more readable version consisting of one SGI double word (64-bits) of data per line. It assumes that the input file is made up of 36-bit words containing ECC bits. This utility is helpful when trying to interpret results from the stub output files.
Use: convert_sram_to_dw input_file [output_file]
Default output file: convert_sram_to_dw_output.dat
convert_dw_to_sram_good_parity.c
This program takes a file containing one SGI double word (64-bits) of data per line, calculates ECC and outputs a file that can be loaded into SRAM for simulation (36-bits of data with ECC per line).
It assumes the input file contains the correct number of lines to fill the SRAM. This utility is useful when you want to input specific data to an SRAM and skip the DMA process in simulation.
Use: convert_dw_to_sram_good_parity input_file [output_file]
Default output file: convert_dw_to_sram_good_parity_output.dat.
command_fields.c
This program takes an SSP command word, splits it into its SSP fields and outputs the SSP field information to the screen. The utility provides this data in the same format as the get_fields.h function in the SSP stub. This feature is potentially useful in debugging from the Virsim viewer.
Use: command_fields 32-bit_hex_value
check_alg_data_flow.c
This program uses the SRAM output file to check data against input data. It takes data input from init_sram0_good_parity.dat and init_sram1_good_parity.dat, removes ECC, and performs a byte-sort on this data (byte-sorts each 8 byte quantity as done by alg_data_flow_v).
The program compares the result to the data in the final_sram2.dat and final_sram3.dat files (with ECC removed). As the comparisons are done, the program prints the byte-sorted input data on the left and the results from the final data on the right. If there are differences in the data, it prints "ERROR" on the corresponding line. The program exits after finding a specific number of errors (adjustable in the source code).
check_alg_simple.c
This file is an example of a program that uses the SRAM output data file to check data against input data. It takes the SRAM0 and SRAM1 input data in init_sram0_good_parity.dat and init_sram1_good_parity.dat and calculates the results of a A & B | C. It then compares its expected data to the data in the files final_sram2.dat and final_sram3.dat (the default output for SRAM2 and SRAM3, respectively). As it proceeds, it prints out the results of each double word result D: on the left, what it expects based on the input data, on the right, what it is seeing in the final results. If there are discrepancies in the data, it prints "ERROR" on the line in question.
The code is set to exit after it finds 64 errors, but this number can be raised or lowered easily (line 60).